Chapter 2: Refactoring and design
An essential part of TDD is refactoring: improving the structure of the code without changing its observable behavior. TDD's tests provide a feedback mechanism: if something is hard to test, it means the code's design needs improvement. When learning TDD, listening to your tests and learning about design is what takes the longest.
Evolutionary design
aka incremental design, aka continuous design
Designing a whole system up-front without mistakes is impossible. At the start of a project is the time when we know the least about the problem we are solving. That's why our design must evolve as we learn more. We put our learning back into the program by modifying it to look as if we had known what we were doing all along, and as if it had been easy to do. [1]
We should start with an idea of a design, but assume it's wrong. [2] We'll continually look for signs that our current design doesn't fit the problem, and then we'll modify the design to fit it better.
But we shouldn't build flexible and reusable components up-front. They would increase complexity and anyway might not flex in the right direction. Instead, we'll follow the principles of YAGNI and Simple Design to reduce the friction of changing our design into any direction.
Four elements of simple design
In priority order:
- Passes its tests
- Minimizes duplication
- Maximizes clarity
- Has fewer elements
With TDD, point 1 is a given. If points 2 and 3 are covered, then point 4 rarely comes up. The order between 2 and 3 is debatable. Thus, the rules can be summarized:
- Remove duplication
- Improve names
Keep practicing these, and in a few decades every other design principle and pattern will emerge.
Duplication
The Don't Repeat Yourself (DRY) principle says:
Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.
- Andy Hunt and Dave Thomas, The Pragmatic Programmer (1999)
The alternative is to have the same thing expressed in two or more places. Then if you need to change one place, you might accidentally not remember to change the other place, leading to problems.
A common case of duplicated knowledge is similar code in two or more places. If the places are almost similar, first try to refactor them to be exactly the same code, after which it's easier to extract the common code to a shared function.
Three strikes and you refactor
aka rule of three
If it's not yet obvious that in what way the duplicated code will vary from place to place, let the code fester/ripen a bit longer. Wait until the code is repeated in three places, and then refactor. This reduces the risk of creating the wrong abstraction. [1]
Naive duplication
Not all code that looks similar is duplicated knowledge. Even if chairs and dogs both have 4 legs, the 4s are not related.
In Conway's Game of Life, the calculation of whether a cell will be alive in the next generation could be written like this:
will_live? = if alive?
neighbors == 2 || neighbors == 3
else
neighbors == 3
The neighbors == 3 is repeated, so let's remove the duplication:
will_live? = (alive? && neighbors == 2) || neighbors == 3
But this is wrong. It couples together two unrelated concepts:
In the original code, the 2 and 3 in the alive? branch are related to the concept of a "stable neighborhood", whereas the 3 in the not alive? branch means "genetically fertile neighborhood".
By naming these concepts it becomes clear that they are not actually duplicated:
will_live? = if alive?
stable_neighborhood?
else
genetically_fertile_neighborhood?
Naming things
There are only two hard things in Computer Science: cache invalidation and naming things.
- Phil Karlton [1]
Removing duplication and improving names feed into each other in a virtuous cycle.
Naming is a process: nonsense → accurate-but-vague → precise → meaningful. Never stop improving.
Composed method
Divide your program into methods that perform one identifiable task. Keep all of the operations in a method at the same level of abstraction. This will naturally result in programs with many small methods, each a few lines long.
- Kent Beck, Smalltalk Best Practice Patterns (1996) [1]
Each new method is an opportunity to introduce a new name.
The code should read like a newspaper article. First the high-level overview, then dig deeper into more details.
Keep in mind that each refactoring can be done in two directions: If you inline everything into one big method, it may be possible to see a different way to split it into small methods.
Small, safe steps
To do a refactoring with far-reaching consequences, you have two options:
- One big change: Carefully analyze the whole codebase to figure out every place that must be changed, and then change all those places at the same time. It may take hours to read the codebase and you could still miss some side-effect. When tests break after your changes, the problem could be anywhere in the codebase.
- Many small changes: Plan a series of changes, each of which can be proven through local reasoning to not change behavior. Start the refactoring from one place and propagate it in tiny increments by making mechanical changes which require very little thinking. There could be 10 or 100 times more steps, but each of them takes just a couple seconds. When tests break after your changes, the problem should be near the line you changed 5 seconds ago.
Many small changes is faster than one big change.
When you refactor, don't change behavior. When you change behavior, don't refactor. Maintain three points of contact like a mountain climber. 🧗
Refactoring hell
If it's been more than a few minutes since the tests last passed, git reset --hard and try again using smaller steps.
(Your IDE's local history may also show when all tests last passed, so you can revert to that point in time.)
Four strategies
There are four strategies to refactor and design using small, safe steps:
- Leap: The change is small enough. Just do it.
- Parallel: Build the new solution side-by-side with the old solution, until the new can replace the old.
- Stepping stone: You want to build thing A, but if you built thing B first, that could make it easier to build thing A. (Beware of gold plating.)
- Simplification: Solve a trivialized version of the problem first. 1×1 sudoku.
Design is scale-free. The parallel change strategy works the same way regardless of whether we're adding a new field to a class, or replacing the healthcare software system of a city.
Test quality
Tests should be sensitive to behavior changes and insensitive to structure changes.
Each test should test only one thing.
Each bug should cause only one test to fail.
From the pattern of failing tests, it should be possible to guess in which function or line the problem is.
If some code can be commented out and no test fails, the code should be dead.
In five seconds you will have forgotten over half of your working memory. Make the tests so fast that you won't forget what you were thinking.
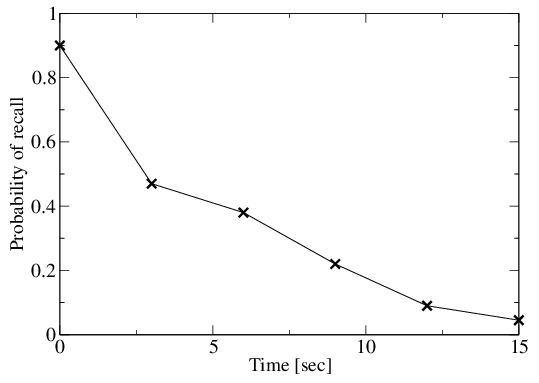
Test smells
Like there are many code smells, there are also test smells. Here are a couple to look out for:
Many asserts per test: Normally tests are structured in the Arrange-Act-Assert/Given-When-Then/Hoare Triple format. But if they are instead Arrange-Act-Assert-Act-Assert-Act..., that usually indicates that a test is lacking focus and testing many different things (making the test's purpose harder to decipher), or that it's testing how the system does things instead of testing what the system does (making refactoring harder). Depending on the testing framework, earlier test failures may also mask later test failures, making it harder to know why the test failed. Instead, write many small, focused tests.
Complex test setup: If the arrange part of a test is long, requiring the careful arrangement of many collaborators to get the system into the desired initial state for the test, it may indicate design problems in the code. Lots of constructor arguments is a similar smell (which is why dependency injection frameworks are best avoided - they make it too easy to add dependencies). Instead, try to think of a design which eliminates some of the dependencies.
Proceed to Chapter 3: The Untestables or Exercises